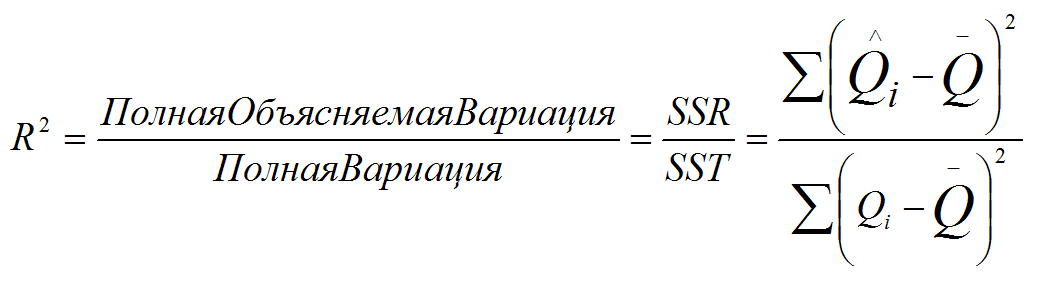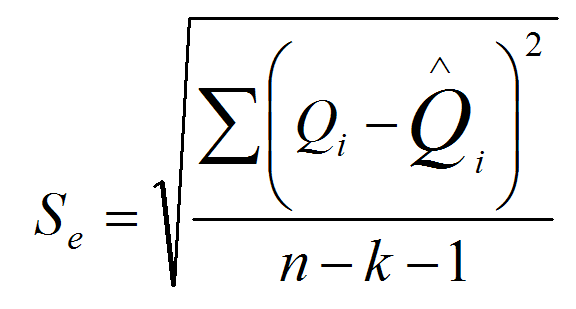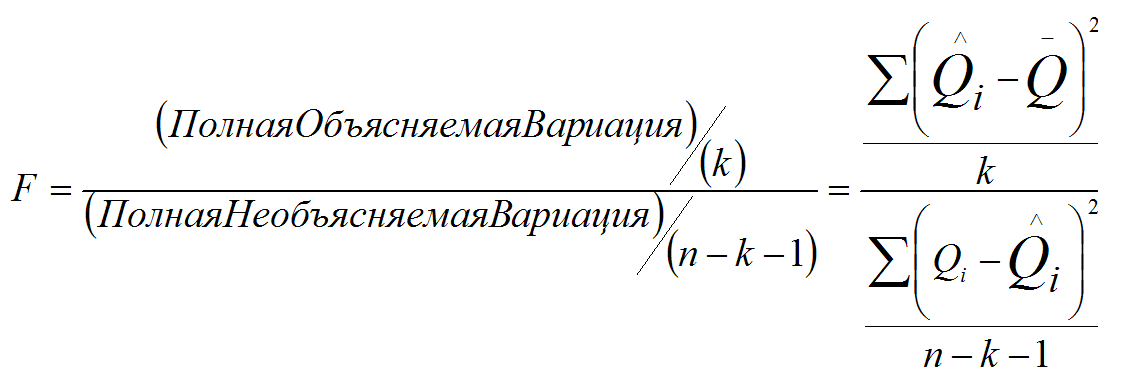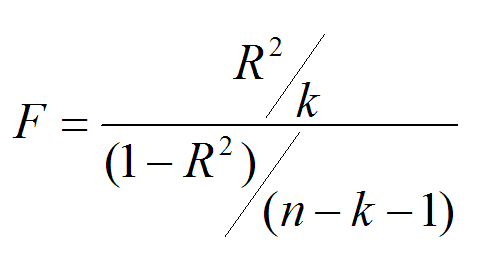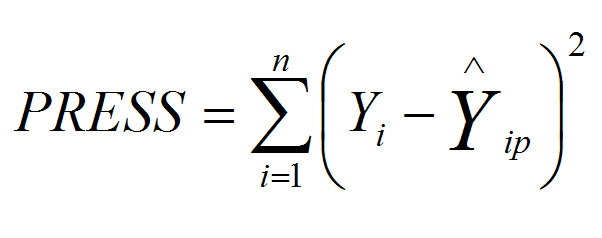Модель должна описываться целевой функцией, дополненной системой ограничений, и опираться на классические теории производства (ее производственной функции), затрат, мотивации, и быть расширена особенностями отрасли, регионов, стран. Мотивационная модель, должна рассматриваться в интерпретации, учитывающей конкурирующий рынок инжиниринговых фирм. Благодаря этому она будет отражать наиболее оптимальный уровень управления технологиями, персоналом и обеспечивающим их капиталом, сложившимся на конкурирующих фирмах через призму трудовой мотивации, как главного механизма эффективного и устойчивого развития фирмы.
На следующем этапе экономическое описание мотивационной модели необходимо расширить ее математической интерпретацией. Отобранный математический аппарат должен корректно описывать происходящие в мотивационной модели линейные, нелинейные, периодические или непериодические, вероятностные экономические процессы, а также аппроксимировать одномерные и многомерные подсистемы мотивационной модели многомерными функциями. Учитывая многообразие возможных форм и систем мотивационной модели и процессов, происходящих в ней, можно априори утверждать о существовании множества этих функций и критериев, способных оценивать экономическую корректность модели и ее статистическую значимость. Математики при описании сложных, функциональных, вероятностных зависимостей нашли пока единственный способ описания сложной функции с помощью набора азбучных зависимостей. Нам предстоит их определить для наиболее корректной аппроксимации (подгонки) мотивационной модели. И дополнить их множеством корректных критериев, способных из практически бесконечного множества вариантов модели, отобрать единственно возможную оптимальную модель.
Остановимся на одном существенном моменте на этимологии слов аппроксимация, подгонка, которые означают одно и тоже – приближение.
Авторы большинства работ свои методы, способы вычислений называют таким образом, чтобы вызвать на ассоциативном уровне у читателя понимания сущности предлагаемого. Зачастую это приводит к разночтениям. Так, в статистической литературе, в работах численного анализа часто приходится сталкиваться с различными названиями одних и тех же, подчеркнем, на первый взгляд, методов, способов вычислений. Это сложилось исторически и связано:
С одной стороны, с неточностями перевода, плохим знанием переводчиком специальной терминологии, неграмотностью научных редакторов.
С другой стороны, принадлежностью тех или иных исследователей к различным школам.
С третьей стороны, с развитием способов вычислений, приводящим к существенному изменению сущности уже существующих методов.
Не менее интересно мнение Даля, который считал, что одно и тоже понятие в различных регионах мира может и имеет право иметь множество определений, иначе порождается убогость языка и невозможность объемного описания сложных понятий.
Одна из известных в РФ функций, как сплайн (англ. Spline) функции, на западе известна как функция гибкой линейки. Эконометрику, биометрику называют также вариационной статистикой. Можно вспомнить и другие определения – на западе метод складного ножа (бойскаутский нож), в РФ метод Кенуя, поправка на смещение, метод расщепления и т.п.
Или другой пример, статистики, чтобы описать вычислительный процесс с искаженными выборками, говорят – «исправить», «откорректировать», «отремонтировать» и т.д. полученную выборку. Когда математики хотят плавно соединить несколько функций, они говорят: "склеить", "сшить", "сгладить" функции.
То же самое произошло и с классическим понятием аппроксимация. Данный вычислительный метод в начале позволял описать некоторую исходную функцию f(x), заданную табличным способом, другой более простой полиноминальной функцией j(x) (канонический полином, полином Лагранжа, Ньютона и т.д.), используя матричную алгебру. Это позволяло, подчеркнем, сразу наложить на f(x) функцию j(x) и определить ее аналитическое выражение.
Но процесс численных, вычислительных решений существенно нелинейных, гладких и/или негладких, не дифференцируемых многомерных зависимостей, в том числе систем уравнений, в РФ и на западе в специальной литературе и программном обеспечении называют подгонкой. Т.к. данное слово, по мнению большинства авторов, более точно отражает вычислительный процесс поиска решения с помощью перебора и/или случайного поиска большого множества существующих элементарных функций, их комбинацию, с последующей склейкой или сшиванием полученных зависимостей. Например, сшивание различных функций можно осуществить с помощью металлической гибкой линейки – сплайн функций, в рамках начальных, граничных условий, которые в свою очередь не линейны по выбранным критериям.
Поэтому в специальной литературе существует набор терминов, взаимодополняющих и расширяющих тот или иной метод.
В работе применялось ПО "Инвест" фонда "Ноосфера", которое позволяет решать проблемы более широкого круга, чем классическая аппроксимация. По нашему мнению, лучше придерживаться точки зрения большинства, которое более корректно, точно по смыслу описывает данный процесс, называет его подгонкой для сохранения целостности, корректности, и смысловой полноты данного понятия, более широкого, чем классическое – аппроксимация.
В период исследования перед авторами стояла проблема, известная всем экономистам. Трудозатраты на построение эконометрических моделей даже при наличии полностью собранного статистического материала составляют от 50% и более от общего объема временных затрат на исследование. Конечно, можно применить предлагаемые на рынке статистические пакеты. Но их универсальность и закрытость создают больше трудностей, чем удобств. Кроме этого они навязывают экономисту определенное стереотипное мышление, что авторов не устраивало. Поэтому авторами было разработано собственное программное обеспечение, которое позволило сократить трудозатраты при построении 5-10 тысяч факторных моделей до нескольких минут. В тоже время объем получаемых моделей все равно подавлял своим количеством. Поэтому был написан дополнительный программный пакет, который выдавал не только графики, таблицы, эконометрические модели, но и описывающий их текст. Это позволило снять всю рутинную работу и сосредоточить внимание авторов исключительно на экономических проблемах. Если бы авторы включили только постановочную часть программного пакета итоговой деловой игры "Инвест", то объем книги вырос бы в десятки раз. Здесь даны только отдельные элементы, которые, по мнению авторов, могут заинтересовать читателя. Подчеркнем, что основной проблемой западной эконометрической школы является то, что математика превалирует над экономикой. Это можно понять, ведь вычислительные мощности в прошлом веке были ничтожны по сравнению с сегодняшними мощностями. Программный продукт авторов полностью убрал эту проблему. Математика это просто инструмент, даже если используется нейронное моделирование. Лучшим доказательством правоты авторов является то, что за последние 60 лет эконометрики ни разу не дали точного прогноза хотя бы на один кризис из прошедших 18-ти в отличие от авторов.
Слово подгонка наиболее полно описывает, ассоциирует (и поэтому подсознательно, интуитивно, что сразу понятно всем) с работой портного, который сначала с помощью множества лекал в целом кроит одежду, но окончательно подгоняет, а не аппроксимирует, далее склеивает, сшивает ее уже на заказчике с помощью линейки - сплайн функциями. При этом перебор лекал и их совокупное множество практически неограниченно.
И в заключении, известный советский математик, который слыл также большим знатоком русского языка, академик A. Колмогоров в своей редакции работ Мориса Г. Кендалла так описывал процесс регрессии.
По нашему мнению, мы не имеем права неуважительно относиться к авторитетам мирового уровня - нобелевскому лауреату, академику А.H.Колмогорову, который постоянно боролся с загрязнением русского языка.
На основании выше изложенного в нашей работе слово-паразит "аппроксимация" по определению A.H.Колмогорова, нами было заменено словом "подгонка".
Таким образом, нам необходимо построить на основе подгонки систему уравнений целевой функции мотивационной модели персонала эффективной, конкурентоспособной инжиниринговой фирмы строительной отрасли и ее ограничений в рамках теорий производства, затрат, мотивации, дополненных особенностями отрасли, регионов, страны и системой математической интерпретации модели в рамках корректного множества критериев оценки ее экономической и статистической значимости.
Только в рамках двух систем уравнений и их ограничений, экономических и математических, можно получить оптимальную экономико-математическую мотивационную модель инжиниринговой фирмы строительной отрасли. Исходя из выше изложенного должны быть:
· Построены две подсистемы экономической и математической интерпретации мотивационной модели инжиниринговой фирмы строительной отрасли.
· Разработаны алгоритмы сбора, обработки статистических данных, необходимых и достаточных для построения мотивационной модели.
· Собраны и обработаны статистические данные. Построена мотивационная модель персонала эффективной, конкурентоспособной инжиниринговой фирмы строительной отрасли.
· Выстроена система нормативов, ограничивающая n-мерное пространство эффективного, конкурентного управления технологиями, персоналом и обеспечивающим их капиталом, базирующаяся на системе критериев трудовой мотивации персонала.
· Сделаны выводы и даны рекомендации по использованию данной модели на практике потребителями, руководителями и собственниками (акционерами) инжиниринговых фирм, кредиторами и инвесторами, налоговыми службами, региональными и федеральными властями.
Любое экономическое исследование опирается на предварительное априорное утверждение (гипотезу) автора, описывающее его представление об исследуемой экономической системе. Единственный способ провести количественную и качественную оценку любой экономической системы это применить эконометрический анализ, без этого любая даже самая гениальная идея (гипотеза) останется бездоказательной фантазией автора.
При изучении различных экономических статистических данных исследователь вынужден постоянно опираться на следующие существенные допущения.
1. Не все имеющиеся статистические данные можно отнести к предикторным (аргументам, экзогенным, независимым, факторным) переменным X1…Xn. Можно с высокой долей вероятности предположить, что некоторые из переменных Xi, отобранных исследователем, являются избыточными и/или они на самом деле реально не объясняют (не являются значимыми) эндогенную (зависимую, отклик) переменную Y. Поэтому при проведении аппроксимации (подгонки) статистических данных исследователь с помощью ПО должен отобрать из исходного набора переменных X1…Xn необходимое и достаточное количество статистически и экономически значимых переменных X1…Xk , наиболее полно объясняющих эндогенную (внутреннюю, зависимую) переменную Y. При этом должно выполняться условие - количество отобранных переменных должно быть меньше и/или равно исходному количеству переменных, т.е. k£n. При этом величина исследуемой выборки должна быть значительно больше, чем количество отобранных переменных X1…Xk.
2. Многие исследуемые сложные многомерные стохастические системы и процессы, происходящие в них, такие как физические, химические, социально-экономические и т.д. могут быть подогнаны различными функциями Z1…Zm. Эти функциональные зависимости можно разделить на линейные (квазилинейные – внутренне линейные, т.е. приводимые к линейным функциям с помощью различных преобразований) и нелинейные (внутренне нелинейные). При этом эти зависимости, независимо от их сложности, могут быть аппроксимированы набором элементарных функций Z1…Zm. Каждая из функций Z1…Zm может объединять различное количество значимых переменных X1…Xk или равно им Z=X (посему зачастую m много больше k, т.е. m>>k), и как следствие наиболее полно можно объяснить эндогенную переменную Y.
3. Отметим последнее предположение. Аппроксимирующие функции могут быть представлены в следующих видах: аддитивном, мультипликативном, и/или их комбинациями.
Учитывая, выше приведенные замечания, исследователь должен рассматривать все множество возможных вариантов, которое можно представить в векторной форме в виде:
Краткий аппроксимирующий набор как линейных, так и нелинейных функций Z1…Zm представлен в ниже приведенной таблице 4.1.1.
Решить эту многовариантную задачу по наиболее достоверной аппроксимации (подгонке) n-мерного статистического пространства выше представленными функциями и их комбинациями невозможно ни физически, ни практически, если не сформировать систему наиболее достоверных критериев оценки по выбору наиболее статистически значимой функциональной зависимости.
Для лучшего понимания вышеописанных проблем рассмотрим их на примере построения производственной функции для случайно отобранных инжиниринговых фирм.
При построении производственной функции пока ограничимся шестью вводимыми факторами. Данную функцию можно представить в виде уравнения:
Q= (X1, X2 ,..., X6), (4.1.2.)
где Q – выручка или объем продаж, являющаяся функцией вводимых факторов производства, X1, X2,..., X6.
Исходные статистические данные были получены из стандартных российских отчетных бухгалтерских форм 1-5. Источник данных: Internet база "Программы раскрытия информации" ФКЦБ РФ. Эти данные были обработаны и преобразованы в международный стандарт IAS, необходимость обработки и преобразования будут пояснены далее.
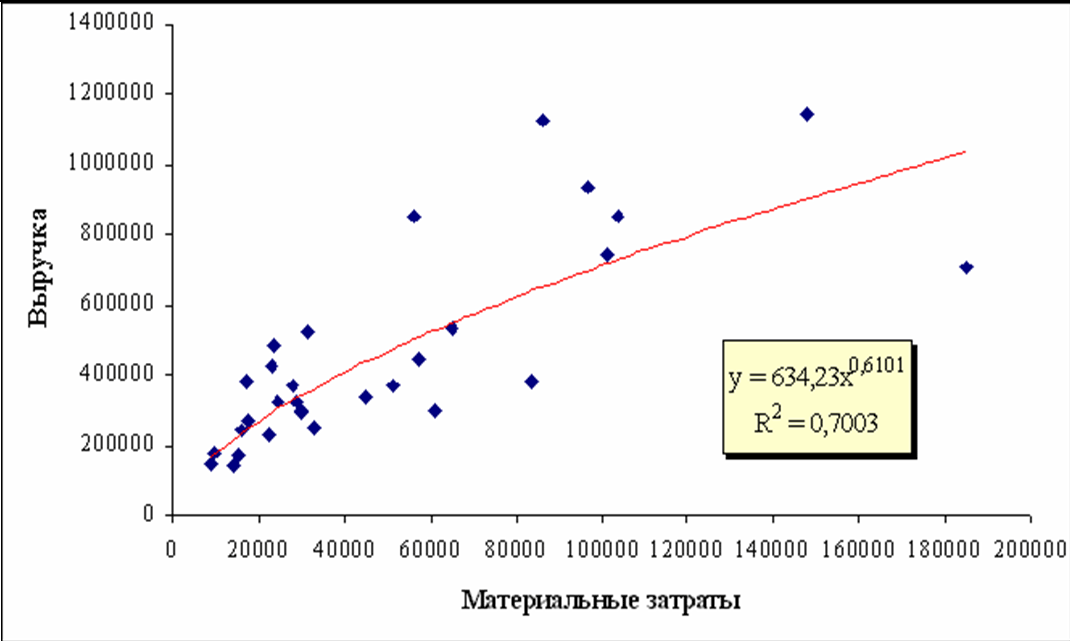
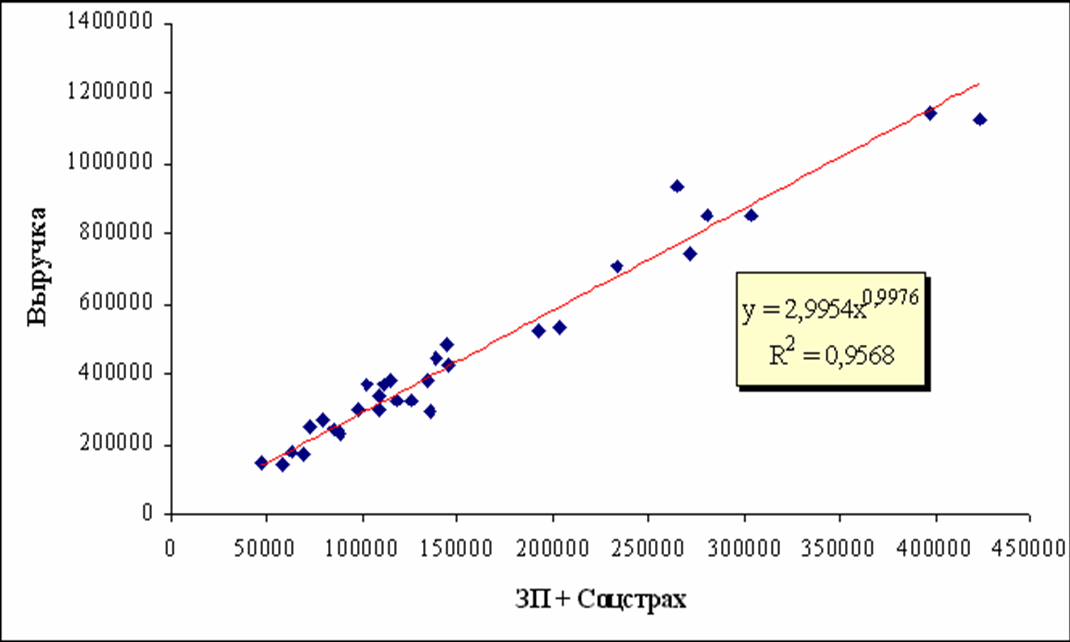
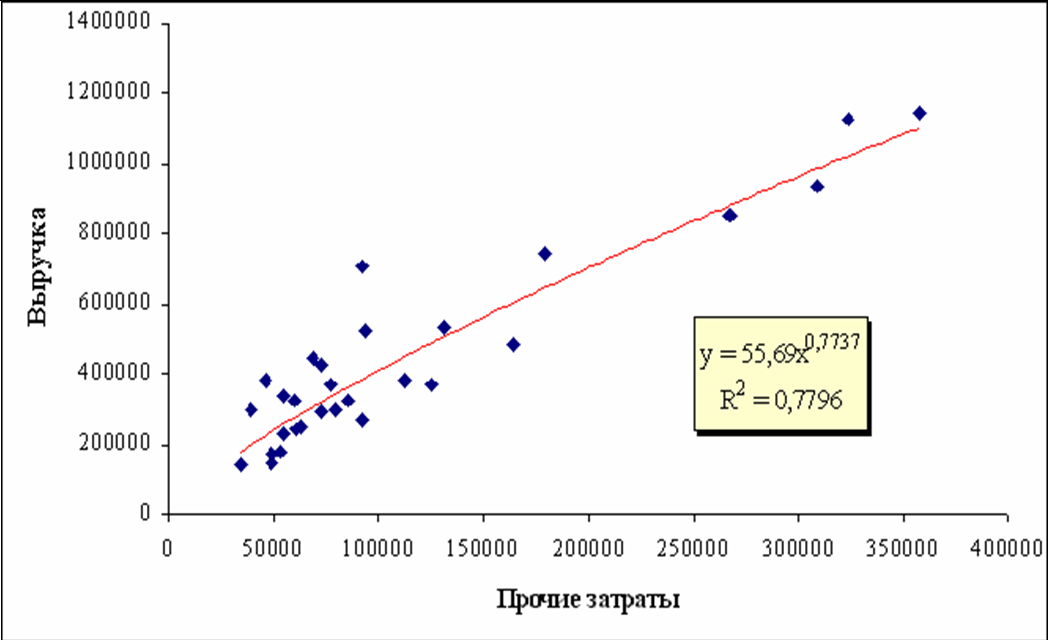
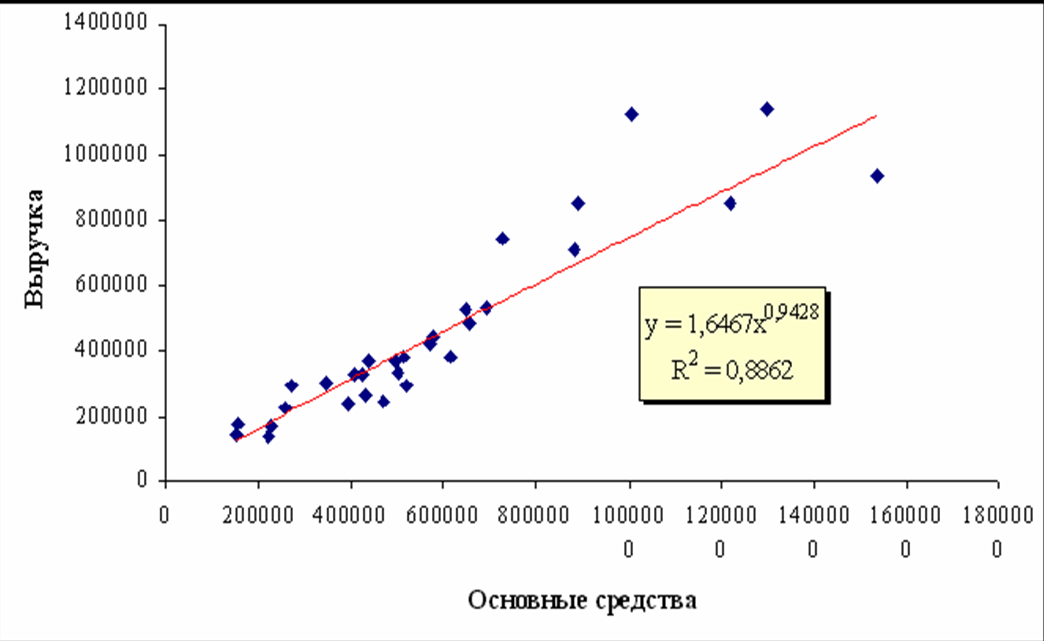
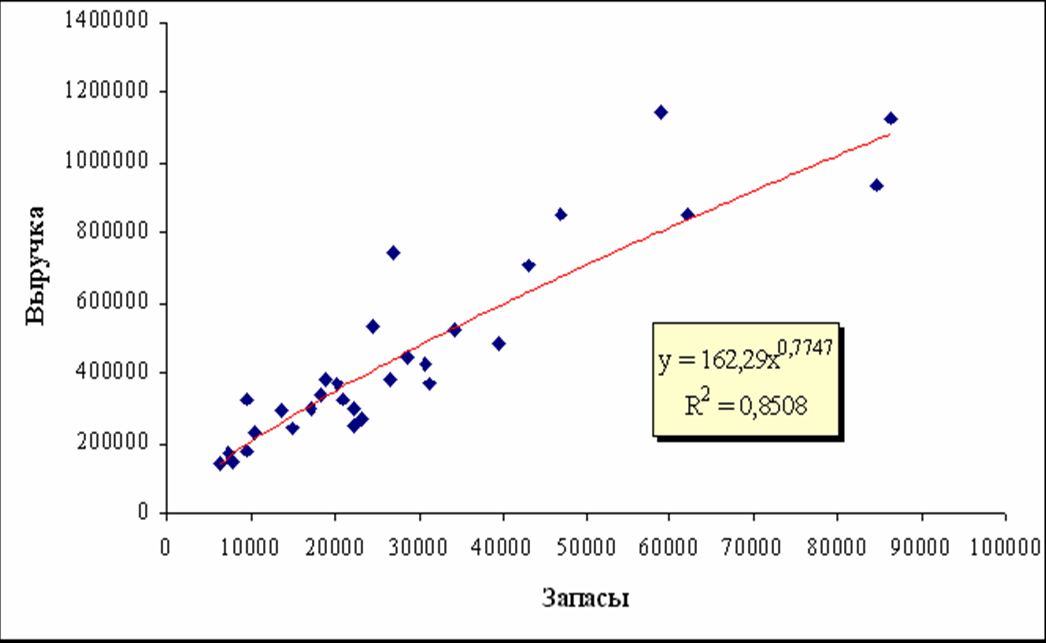
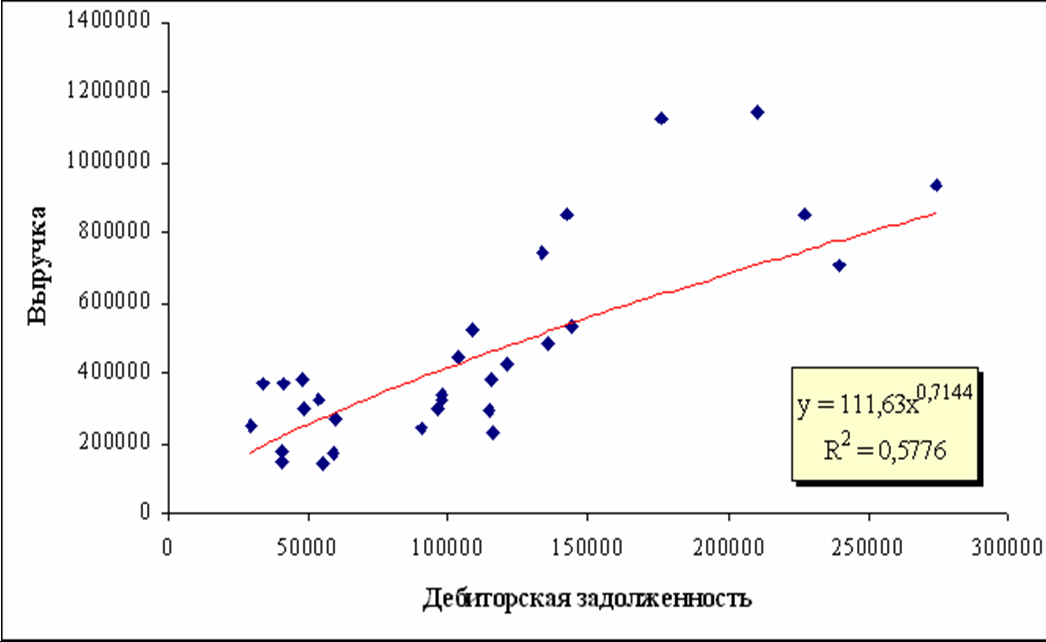
Однофакторные модели зависимости Q=(Xi) можно представить графически на рисунке 4.1.1.
Линия на графиках представляет собой регрессионное уравнение степенной аппроксимирующей функции, одной из многих рассмотренных ранее в таблице. Точки на графиках означают статистические данные случайным образом отобранных исследуемых предприятий. При этом они расположены выше и ниже линии.
Даже несложный зрительный, экономический, пофакторный анализ показывает, что эффект отдачи от масштаба (с ростом объемов производства затраты падают) присутствует, т.к. эластичность меньше 1, т.е. с ростом затрат объемы продаж (выручка) растут, но с меньшей скоростью – все степенные коэффициенты меньше 1.
Возникает естественный вопрос хорошо это или плохо, и как обстоят дела в аналогичных инжиниринговых фирмах в развитых странах?
Пока мы можем ответить на один вопрос. Ранее при построении многомерной мотивационной функции мы получили однозначный ответ, экономика РФ находится в мотивационной яме, т.е. устойчиво деградирует. Может ли в этих условиях малый элемент экономики, в нашем случае ИФСО, развиваться хотя бы на уровне, по нашему мнению, несовершенной экономики США, которая в 20-30 раз более эффективна, чем российская экономика. Интуитивно понятно, что ИФСО РФ не будут демонстрировать более эффективное состояние, чем их конкуренты в США. Таким образом, эти графики показывают, как развиваются ИФСО в условиях мотивационной ямы РФ и не более. Данное утверждение голословно, т.к. оно опирается на интуитивное ощущение исследователя и косвенные расчеты по многомерной мотивационной модели. Для того чтобы решить эту проблему, экономисту необходимо дополнительно исследовать на уровне межгосударственного сопоставления межотраслевые балансы США, спустившись до уровня строительной отрасли, ее подотраслей и, частности, ИФСО. Рассмотреть все взаимосвязи и построить модели и их взаимосвязи с предприятиями других отраслей и подотраслей, которые воздействуют и определяют развитие предприятий строительной отрасли, в т.ч. и ИФСО. Т.е. рассмотреть все многообразие прямых и обратных связей, как развитие ИФСО будет влиять на все отрасли экономики, и как эти отрасли будут влиять на ИФСО. Когда эта условная эталонная модель предприятий США будет получена, то далее следует эту эталонную модель погрузить в российскую среду. Результаты данного исследования можно посмотреть в книге авторов "Анализ хозяйственной деятельности предприятий строительной отрасли".
|
|
|
|
|
|
|
|
|
Отметим ряд моментов.
Во-первых, авторы считают, что экономика США, конечно, значительно более эффективна, чем экономика РФ. Тем не менее, она остается несовершенной по сравнению с ноосферной экономикой. Если бы она была эффективной и развивалась бы на уровне ноосферной экономики, то не было бы систематических экономических и финансовых кризисов. Поэтому построение этой эталонной модели условно эффективной экономики США, должно производиться с учетом поправочных коэффициентов (функций), которые корректируют полученную модель в направлении ноосферной экономики. Зачем российской экономике повторять регулярные ошибки США. По нашему мнению, к сожалению, экономика США пошла по российскому пути и подсела не на сырьевую, а на финансовую иглу. Потому утверждение министра финансов США о хорошо сбалансированной экономике сомнительно. Примером служит бывший центр автомобильной промышленности Детройт. Межотраслевой баланс США свидетельствует о том, что мультипликатор автомобильной промышленности составляет 3.0-3.5. Т.е. рухнувшая автомобильная промышленность негативно воздействует на предприятия других отраслей США с силой этого мультипликатора, а те в свою очередь подобно ядерному взрыву со своими мультипликаторами, большинство из которых больше 2.0, воздействуют как на автомобильную промышленность, так и на предприятия других отраслей. А столь любимая американцами финансовая игла, к сожалению, мультиплицирует экономику лишь на 1.3-1.5 раз. И потом финансовая система была вторичной по отношению к предприятиям отраслей реальной экономики и является посредником между домашними хозяйствами и предприятиями реального сектора. Когда реальный сектор сокращает объемы продаж или вывозит свои производственные активы в третьи страны, то увеличивается безработица и тоже мультипликативно. В результате беднеющие домашние хозяйства снижают платежи через финансовую систему США. Это является причиной регулярных финансовых и экономических кризисов и, в частности, последнего ипотечного кризиса 2008-2009 г.г. Воистину библия права: тот, кто не платит своим работникам, и как следствие не мотивирует их труд, в результате оказывается банкротом.
Во-вторых. Рассмотрев причину условной эффективности экономики США, перейдем к процессу погружения эталонной модели США в российскую среду. Налоговая система, процентные ставки, оплата труда, цены на товары и услуги, процент прибыли, амортизация и т.д. в США отличны от показателей РФ. Данный пересчет, несмотря на кажущуюся сложность, осуществляется легко. Все необходимые данные представлены в Интернет базах данных США. Например, в базах данных министерства труда можно узнать не только среднюю оплату каменщика, плотника и топ менеджеров, но и эти данные по любому городу и штату. На сайтах штатов, городов и министерства финансов можно узнать налоговые ставки для предприятий любых отраслей. В ФРС США не сложно посмотреть процентные ставки и льготы для предприятий любых отраслей. В базе данных ФКЦБ США можно получить публичные отчеты любых предприятий США. В результате можно сформировать все коэффициенты, которые необходимо будет откорректировать в соответствии с российским законодательством. В итоге мы получим эталонную модель американских предприятий, погруженных в российскую среду или как бы условно работающих в РФ.
В-третьих. Получив эталонную модель американских предприятий, можно использовать и сравнивать ее с ранее построенными моделями и, как следствие ответить на вопрос, эффективно или неэффективно работают российские предприятия, и как обстоят дела в аналогичных инжиниринговых фирмах в развитых странах? Сегодняшние аналитические российские службы, в том числе министерств и ведомств этого не делают. Поэтому не удивительно, что их выводы ничего общего не имеют с реальностью. Данный алгоритм и полученные модели по финансовой системе США и строительной отрасли даны в предыдущих книгах авторов.
По статистически непроверенным данным для современных эффективных, конкурентоспособных компаний развитых стран данный факт является анахронизмом. Для компаний РФ это свидетельствует о низком уровне управления технологиями, персоналом, капиталом в исследуемых компаниях. О полном отсутствии в этих компаниях эффективных собственников, профессиональных менеджеров, прогрессивных технологических тенденций и трудовой мотивации персонала, соответствующей рекомендациям МОТ и требованиям стандарта ISO. Последнее, в частности, объясняется практически "рабским, физиологическим" уровнем оплаты труда персонала.
Выше говорилось только о 12 простых функциях (пункт 2), с помощью которых можно подогнать регрессионное уравнение.
"Какие из этих функций наиболее точно (с минимальными ошибками – точки должны находиться на минимальном расстоянии от линии) смогут описать эту, даже зрительно видимую, функциональную зависимость?".
Все ли переменные X1,X2,...,X6 статистически и экономически значимо (достоверно) объясняют Q выручку (объем продаж) или их количество необходимо уменьшить, или их достаточно, или количество переменных необходимо расширить?
В каких видах аппроксимирующие функции могут быть представлены в аддитивном (сложение), мультипликативном (умножение), и/или их комбинациями?
Последний вопрос, несмотря на внешнюю простоту сложения и умножения, также не банален. Сложение и умножение это практически азбучные операции всей математики. Из этих кирпичиков можно построить любые математические зависимости.
В целом для данной задачи необходимо как минимум перебрать 26*12*3=2304 варианта и отобрать самый эффективный (оптимальный) единственный вариант.
Где 26 – это количество переменных X1, X2 ,...,X6, если бы их было 15, то это была бы величина 215 .
12 - это минимальное количество элементарных функций.
3 - это минимальное количество комбинаций сложения, умножения и их комбинаций.
Как видно, даже для этой не столь сложной задачи решить ее без эффективной системы критериев невозможно.
Еще раз напомним, нам необходимо так подогнать уравнение (функцию) регрессии, чтобы исходные статистические данные (точки) находились на минимальном расстоянии от регрессионной линии, как это было показано на рисунках выше. Таким образом, можно сразу сказать, что все критерии без исключения, которые будут рассматриваться ниже так или иначе будут оценивать, исследовать этот разброс (ошибку) статистических данных от уравнения регрессии.
Опишем систему критериев оценки статистической значимости мотивационной модели.
1. Множественный коэффициент детерминации (корреляции) R2. Он должен принимать максимальное значение.
2. Множественный приведенный (скорректированный) коэффициент детерминации (корреляции) R2коррект. Он должен принимать максимальное значение.
3. Критерий Маллоуза СР. Он должен принимать минимальное значение.
4. Стандартная ошибка - S (стандартное отклонение остатков или среднеквадратичное отклонение) оценки уравнения регрессии. Он должен принимать минимальное значение.
5. F-статистика - должна принимать максимальное значение.
или
6. Частный F критерий.
7. Многомерный критерий Хоттелинга.
8. t-критерии - должны принимать максимальные значения, и при этом каждый коэффициент должен быть в 1,7-2 и более раз больше его стандартной ошибки.
9. Press анализ.
Таким образом, нами описана система элементарных функций в ее векторной форме (3.1.1.) и система критериев оценки мотивационной модели, описанных в (4.1.3) - (4.1.7). Ранее была определена мотивационная модель эффективной, конкурентоспособной инжиниринговой фирмы строительной отрасли. Поэтому можно перейти к следующему этапу.
Рассмотрим алгоритм построения мотивационной модели и расчета любых кризисов. Он состоит из следующих подсистем и блоков:
Данная подсистема должен собирать отчетные данные инжиниринговых фирм строительной отрасли. Она должна идентифицировать полученные данные по подотраслевой, региональной, страновой составляющей. Источник данных Internet база данных программы раскрытия информации ФКЦБ, объем информации – квартальная публичная отчетность предприятий (форма 1-5). Периодичность сбора информации один раз в квартал.
Эта же подсистема должна собирать данные региональных властей в части их монетарно-фискальной политики и региональной статистической отчетности. Региональная Internet база данных. Периодичность сбора информации один раз в квартал. Эта же подсистема должна собирать из Internet баз данных ЦБ РФ, ГКС (Росстат) РФ, министерств торговли и развития, труда, финансов. Периодичность сбора информации один раз в месяц. К сожалению, пока в РФ федеральные и региональные власти, в том числе и ЦБ РФ, не предоставляют своим налогоплательщикам и мировой общественности отчетность в том объеме и в той периодичности, как это делают все развитые страны. Данная подсистема должна быть расширена Internet базами данных развитых стран (Internet ссылки в литературе). В первую очередь США (32% мирового ВВП), объединенной Европы (27% мирового ВВП), Японии (15% мирового ВВП) для сравнения Россия (0,8% мирового ВВП) с учетом всех стран СНГ (1 % мирового ВВП). Не сложные расчеты показывают, если в 1985 г. СССР отставала от США в 2 раза, то в результате пятнадцати лет "реформ" это отставание увеличилось в 16 раза. В скобках даны данные World Bank за 2001 г..
Данная подсистема преобразует любые отчетные формы в единую форму международного стандарта бухгалтерского учета (IAS - International Accounting Standards Board, http://www.iasc.org.uk), что позволяет сделать возможным, анализировать любые строительные фирмы из любых стран независимо от принятых в этих странах отчетных стандартов и форм. Без данной подсистемы построение экономико-математической модели невозможно. Это внутренний формат представления статистических данных строительных предприятий в модели.
Данная подсистема также преобразует собранные данные из различных форматов, предоставляемых федеральными, региональными властями, торговыми площадками во внутренний формат данных системы.
Подсистема обеспечивает связь статистических данных, полученных из баз ФКЦБ, региональных, федеральных властей, а также проводит их увязку во времени. Эта подсистема необходима, так как периодичность статистических данных предоставляется в различных временных, числовых размерностях и отличается временем публикации. Например, квартальные отчеты из баз ФКЦБ, ежемесячные отчеты федеральных и региональных властей, ежедневные отчеты торговых площадок.
Данные с пропусками и ошибками это проклятие исследований, в которых используются результаты выборочных обследований: зачастую, увы, невозможно гарантировать, что все предоставляют полную и точную информацию.
Восстановление пропущенных данных и так называемых "выбросов" будем осуществлять по методам ПРЕСС и множественного восстановления. Идея состоит в том, чтобы восстановить данные не один, а несколько раз, оценить требуемые модели с помощью стандартных методов анализа полных данных, а затем подходящим образом обобщить результаты оценивания. Данная подсистема использует бутстрем метод в интерпретации.
Статистические данные, которые нам предстоит обрабатывать, могут описываться с равной вероятностью как линейными, так и нелинейными многомерными функциями. Поэтому данная подсистема осуществляет генерирование данных функциональных зависимостей элементарных, полиномиальных, сплайн функций, а также периодических функций.
Учитывая, что данная модель предназначена для повседневного использования при управлении в инжиниринговых фирмах, считаем необходимым сделать ряд существенных замечаний или дополнений.
1. При моделировании и построении среднеотраслевых эталонных экономических показателей необходимо учитывать неизбежные структурные изменения в показателях, которые будут вызываться тем, что в обрабатываемых статистических выборках будут включены предприятия существенно, например, неоднородные по мощности, по размерам, по объемам реализации (малые, средние, крупные) и т.д. Эти недостатки структурной неоднородности могут быть наиболее эффективно устранены с помощью сплайн функций.
2. Класс линейных, квазилинейных, полиномиальных функциональных зависимостей в процессе подгонки многомерных моделей зачастую не выдерживают критики, поэтому целесообразно также применять сплайн аппроксимацию.
3. Сложившаяся повсеместная практика построения эконометрических моделей предполагает использование только мультипликативных или аддитивных моделей одного и того же класса. Например, степенных, линейных, полиномиальных, что не соответствует реальным процессам в экономике, которые описывает мотивационная модель. Эти модели не только нелинейные по n – мерным параметрам и m – мерным переменным, но и могут использовать комбинации как мультипликативных, так и аддитивных зависимостей, а также могут объединять различные классы функциональных зависимостей.
4. Современные вычислительные системы практически сняли ограничения по скорости вычислений, но и по объемам обрабатываемой и хранимой информации. Поэтому полученные в результате обработки и подгонки n – мерные функциональные зависимости целесообразно представлять не в символьном виде, а в n – мерном матричном виде для последующего использования в оптимизационной подсистеме мотивационной модели. В случае необходимости вычисления промежуточных значений можно легко и незаметно для пользователя получить их с помощью сплайн аппроксимации.
5. Современные экономисты-практики в своей повседневной работе с данной моделью не должны отягощаться всеми математическими изысками, используемыми в данной работе. От них требуется дать экспертную экономическую оценку полученных результатов. Поэтому целесообразно скрыть от них "пугающее" n – мерное функциональное пространство, и "лишить" их необходимости рутинного перебора всех возможных вариантов. Тем более, что сплайн аппроксимация описывается достаточно сложными функциональными зависимостями и системой уравнений.
В целом, данная подсистема призвана упростить работу пользователя, при этом, не снижая уровня достоверности полученных результатов. Генератор использует проверенную базу обширного класса элементарных функций, полиномиальных и сплайн функций. Их комбинация должна позволить осуществить построение выше описанного количества вариантов функциональных зависимостей.
Данная подсистема использует классические линейные и нелинейные методы. Здесь отметим только то, что она опирается на потоках статистических данных и функций, поступающих из генератора функций. Оригинальность данного подхода в том, что данная подсистема объединяет в себе поток данных и поток функций.
Данная подсистема использует методы оценки модели, которые были подробно описаны ранее. Здесь отметим только то, что она управляет двумя потоками – корректирует поток статистических данных, для чего использует бутстреп метод, метод Монте-Карло, и поток функций.
Данная подсистема предоставляет возможность рассмотреть все возможные варианты моделей, которые были сформированы в результате работы предыдущих подсистем. Особенность данной подсистемы заключается в том, что модели ранжируются по степени статистической достоверности, значимости. Исследователю предоставляется возможность отобрать из этого множества те модели, которые, по его мнению, наиболее значимы в экономическом смысле, т.к. зачастую статистически значимые модели могут не всегда согласовываться с экономическим смыслом. Данная подсистема предоставляет возможность исследователю рассматривать не только математические, но и графические образы. Экономисту предстоит решить, согласуется ли она с его экономическими гипотезами или нет.
Ранее при анализе отрасли, региона, монетарно-фискальной политики мы рассматривали необходимые показатели, которые являются доступными для любого исследования в экономически развитых странах. Учитывая, что наша страна всего за 12 лет в результате "реформ" перешла из разряда сверх державы в разряд третьих стран по уровню социально-экономического развития, как следствие многие данные, необходимые для исследования, или просто отсутствуют или существенно искажены и публикуются не периодично. Это потребовало от нас включить в модель данные экспертов, косвенные оценки и т.д.
Приведем лишь несколько примеров.
Из более, чем 5000 предприятий строительной отрасли, зарегистрированных в базе данных ФКЦБ и обязанные по закону в рамках программы раскрытия информации предоставлять свою ежеквартальную публичную бухгалтерскую отчетную информацию реально отчитываются только не более 50, из этих предприятий ни один не предоставляет полную развернутую информацию.
Еще раз подчеркнем отчетные формы, которые предоставляли строительные организации в дореформенный период (1991 г.) по объему и детализации информации соответствовали и даже превосходили объем данных их американских коллег и конкурентов.
В развитых странах рыночная экономика воспринимается как равноправие, возможность получения подробнейшей информации о любой компании, которая выпускает акции, облигации или привлекает любые виды кредитов. Инвестор должен быть защищен от недобросовестных компаний и имеет законное право получать полную информацию от любых компаний, независимо от того будет он вкладывать свои средства или нет. Например, за не предоставление экономических отчетных данных для инвесторов за их недобросовестность и/или не сообщение об ухудшении в перспективе экономического положения компании, то они преследуются по федеральному закону от 1934 года. А топ менеджеры наказываются по уголовному закону. Неудивительно, что США самая инвестиционно - привлекательная страна в мире.
Для оценки функции затрат, производственной функции необходимы, например данные:
О загрузке производственных мощностей предприятия, этот очевидный для всех экономистов параметр просто отсутствует. Пришлось по каждому предприятию его оценивать, комбинируя данные ГКС, экспертов, а в случае отсутствия и этих данных не включать предприятие в выборку. В развитых странах он публикуется ежемесячно, в целом по стране, по регионам, отраслям.
Уровень реальных доходов населения в исследуемом регионе, например, Москва по доходам населения отличается от регионов России в 4-10 раз. Но даже эти данные Росстат РФ публикует только по 10 территориальным объединениям, вместо 89 субъектов РФ раз в год (зачастую они отсутствуют или запаздывают). В развитых странах данный показатель публикуется ежемесячно в целом по стране и по регионам. Например, в США отчет о занятости (Employment Report), отчет отражает ситуацию на рынке труда и включает данные об уровне занятости, количестве новых рабочих мест, средней почасовой оплате труда и продолжительности среднестатистической рабочей недели. Публикуется бюро статистики труда Минтруда ежемесячно (в первую пятницу месяца в 8:30 по E.T.) и содержит данные за прошедший месяц. Оказывает высокое воздействие на динамику торгов, поскольку считается наиболее точным индикатором экономической конъюнктуры. Отдельные разделы этого отчета, в частности, об уровне безработицы и средней почасовой оплате труда, используют при построении инфляционных моделей. Кроме того, данные отчета применяются для прогнозирования других экономических показателей, в том числе размера индивидуального дохода, объема промышленного производства, объема нового жилищного строительства. При анализе средней почасовой оплаты труда наибольшее значение имеет процентное изменение по сравнению с прошлым месяцем, однако иногда также учитывается изменение за год. Общий объем основных экономических ежемесячных отчетов только в США более 200.
ФРС США отчитывается перед своими гражданами и мировой финансовой системой 2 раза в неделю. В этот отчет включены данные и по региональным объединениям США. ЦБ РФ такой роскоши себе не позволяет.
Все эти ограничения потребовали введение в алгоритм бутстреп и Монте-Карло методов. Это позволило нам при наличии ограниченных данных моделировать модели функций распределения тех или иных параметров производственной, затрат, мотивационных функций. Данные методы, к сожалению, не могут обеспечить высокую экономическую значимость полученных результатов на данном этапе - в условиях информационной не прозрачности РФ.
Это решающий этап исследования и построения мотивационной модели. Все предшествующие шаги алгоритма могут быть сведены на нет неправильной экономической интерпретацией управляющими инжиниринговых фирм полученной модели.